Database Terminology Explained: Postgres High Availability and Disaster Recovery
7 min readMore by this author
In my day to day, I'm surrounded by great database engineers. They talk about things like HA and raft protocol and the right and wrong approach for configuring synchronous vs. asynchronous replication. There is a lot of value in all that deep technical knowledge, but for when interacting with customers, I like to boil it down a bit. What I've seen is that for many folks the basics of key database principles can get lost in the details. What follows is a summary of conversations I've had with customers on how to think about key tenants of database management: high availability and disaster recovery.
What Does It Mean To Be Highly Available?
High availability generally means you have a business critical application that needs to be “always on”. Meaning it needs one or more standbys and an automated failover system to achieve business continuity. In the case of database high availability, your core data should exist in at least two separate environments, all of which are up to date, with at least one of them ready to switch to the primary node if your main database fails.
What’s Resiliency Got To Do With It?
I’ve been in tech long enough to remember uptime percentages and contracts with downtime clauses covering cases where there were days of downtime! Nowadays, downtime events like that are rare and the focus on high availability has changed from downtime/uptime metrics to measuring the speed at which your system will fail over to your backup. This is often called resiliency. You should be looking for high availability solutions that are resilient enough to fail over to a new primary in a matter of seconds. If you’re measuring things in dozens of minutes or hours, that’s not high availability.
There’s two metrics that you’ll hear often around high availability failover times and resilience. One is RPO, Recovery Point Objective, and that is the time between your backup copy and your incident, so it measures the tolerance for data loss. For some businesses this might be a few hours or minutes, for others this is seconds. RTO, Recovery Time Objective, is a measurement of time from your incident to recovery and measures your target recovery time.
Disaster Recovery is About More Than Just Availability
Disaster Recovery (DR) is a high-level term referring to a company’s plans to deal with a disaster: either a natural event, a security attack, or some other kind of major failure. Even in the world of cloud your database is still running on some physical infrastructure…it's not located in the sky. This means events like hurricanes can actually put places like us-east in AWS at risk as we saw a few years ago. Backups are the cornerstone of DR. Postgres has a lot of features for managing backups, ranging from log file restores, full system backups, and point-in-time recovery. pgBackRest is a favorite project here and Crunchy developers are some of the major contributors
When you’re talking about backups, you’ll want to be familiar with the term Point-in-Time Recovery (PITR). The general idea of this system is that you’ll make a series of backups all referring to a specific point in time and can restore back to one of those, depending on the type of disaster that occured.

Generally HA is part of a larger disaster recovery plan and system so having HA set up for your data in most cases will meet your disaster recovery needs as well. There might be organizations that do not require HA to meet their DR goals. So in general, I think of HA as something that is DR and then some.
Architecture
Because a high availability scenario requires you to have multiple copies of your data that are separated, you will need to consider the higher level architecture for the machines hosting your data. You also need to consider how your instances are separated. If you have your database on a VM, you don’t want to just make another VM at the same data center or cloud node, because that will likely have the same loss of service as your main instance. In general, for cloud hosting, you want to reserve an instance in a separate data center (or in cloud terms availability zone). For extreme cases of resiliency you could consider replicating across regions or even across different cloud providers.
Replication
If you’re talking about HA, you’re almost surely going to hear about replication, which refers to the mechanism that keeps the databases updated with one another. Obviously, getting the data moved over in a reasonable time is the challenge here, while minimizing lag in data. If you have to failover to a copy of your data, you want that to be ready to go. Having a solid replication practice ensures that in the event of a failure of your main data location, you have a backup copy ready to take on the workload.
There are two flavors of PostgreSQL replication, synchronous and asynchronous. Synchronous replication writes data to multiple locations at the time when the data is stored. Asynchronous replication writes logs data to a replica - and in general that means there can be a small delay in writing the replication info.
In general, PostgreSQL by default uses asynchronous replication for performance. The log data for PostgreSQL will come from the WAL - the write-ahead-log. Streaming asynchronous replication is generally regarded to be ideal for performance.
Here’s a great resource for looking at different kinds of replication and how to accomplish them, check out the Comparison Matrix.
Modern Nomenclature Around Replication
If you go googling on this topic, you’ll see a variety of words used to describe the same things. The terms I used to hear often were ‘master’ and ‘slave’, ‘multi master’ was also frequently used. These have deprecated for modern terms like ‘primary’ referring to the main data source and ‘replica’ the secondary copy instance. Also, the terms ‘active’ and ‘standby’ serve similar purposes. Active being the read-write instance, standby being the copy instance, ready to be read-write if needed. I’ve also heard ‘active’ and ‘standby’ refer to the data centers - so the term active - active might refer to two active write instances of PostgreSQL or two active datacenters.
Monitoring & Alerting
Monitoring is also key to any high availability environment, since the cluster itself needs to know when it is not functioning and take steps to self-heal. We also recommend a dashboard to keep an eye on the overall system health and cluster status. Even if you’re not a DBA or system engineer, try to get access to the monitoring and dashboards. You should also be planning for alerts to key staff and stakeholders of any major event, be it downtime, failover, or even high CPU usage. Any good HA system will have automated alerting baked in.
Containerization
If you’re talking about modern architecture, you’re probably also hearing about containers. Kubernetes technology and the trend towards containerization doesn’t fundamentally change high availability. The terms are mostly the same as is the mechanism for replication. The big difference is that the instance configurations exist as parts of Kubernetes manifests, and ideally are orchestrated by a tool such as the Postgres Operator. The failover mechanics remain similar overall, and can leverage the infrastructure provided by a platform like Kubernetes.
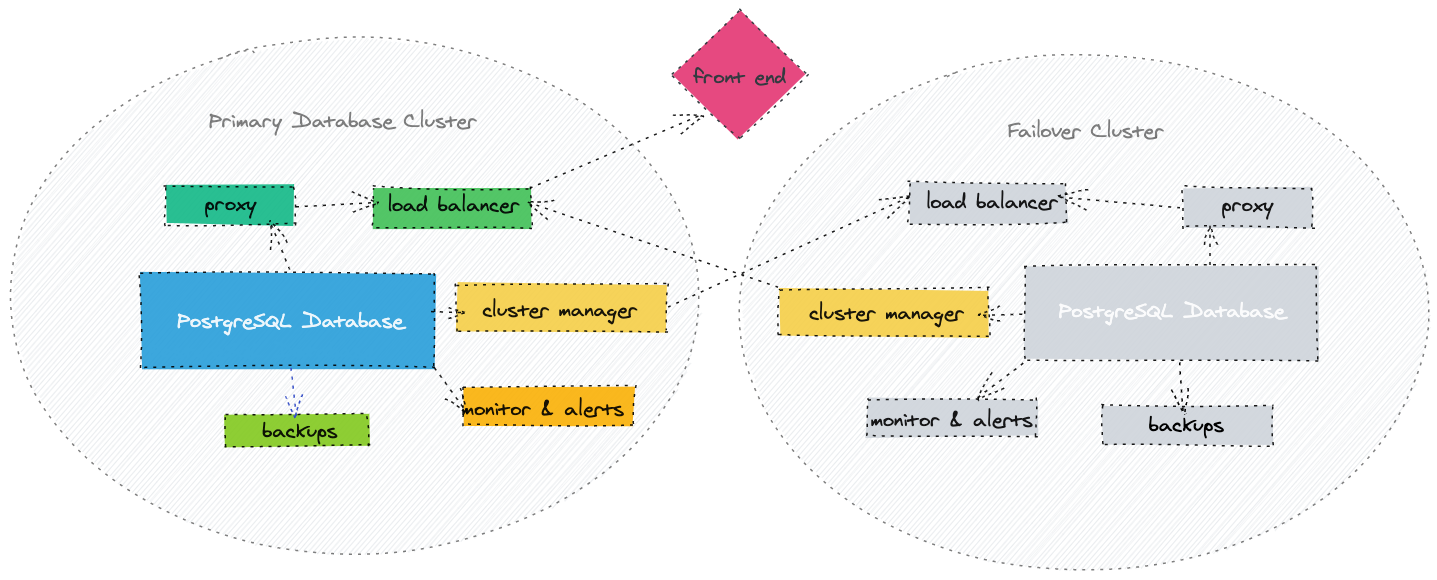
HA Components
At a high level, for an HA database architecture, you’ll have these components:
- Your main database and one or more replicas
- Cluster management and configuration software
- A tool for keeping external IPs the same so you don’t have to update your app code if you fail over to a new database server. This could be an elastic IP or a proxy, or other DNS configurations.
- A monitor for each instance and a dashboard and alert system for each instance
- A backup system
Summary
The technical specifics and implementation of HA can often be complex. You can boil HA Postgres down into a few key topics: monitoring, backups, and replication.
For those of you that never want to get down into the details of asynchronous vs. synchronous replication and RPO vs. RTO, we hope this primer helped demystify things a bit. And for anyone that wants to go deeper and has questions, feel free to reach out to us if you need help.