Latest Articles
- Hacking the Postgres Statistics Tables for Faster Queries
- OpenTelemetry Observability in Crunchy Postgres for Kubernetes
- Creating Histograms with Postgres
- Introducing Crunchy Postgres for Kubernetes 5.8: OpenTelemetry, API enhancements, UBI-9 and More
- Crunchy Data Warehouse: Postgres with Iceberg Available for Kubernetes and On-premises
Range Types & Recursion: How to Search Availability with PostgreSQL
Jonathan S. Katz
12 min readMore by this author
One of the many reasons that PostgreSQL is fun to develop with is its robust collection of data types, such as the range type. Range types were introduced in PostgreSQL 9.2 with out-of-the-box support for numeric (integers, numerics) and temporal ranges (dates, timestamps), with infrastructure in place to create ranges of other data types (e.g. inet/cidr type ranges). Range data is found in many applications, from science to finance, and being able to efficiently compare ranges in PostgreSQL can take the onus off of applications workloads.
Range types work very well in the presence of data: if I have a range, I can efficiently look it up. However, in the case of the absence of data, e.g. storing when dates are booked, but not when they are available, it may take a little more work to perform certain operations, such as looking up date availability. Let's explore a simple scheduling application where these problems occur and see how PostgreSQL already has the tools available to solve them.
Background: Range Notation
To avoid dusting off a precalculus textbook, please recall that:
- [3, 5] = 3 ≤ x ≤ 5
- [3, 5) = 3 ≤ x < 5
- (3, 5] = 3 < x ≤ 5
- (3, 5) = 3 < x < 5
where a bracket means "inclusive" and a parenthetical means "exclusive." [3, 5) defines an integer range with 3 inclusive, 5 exclusive.
For this example, we will be working with the daterange data type. By default, the a daterange is instantiated as a [x,y) type range, so
SELECT daterange('2018-03-01', '2018-03-02');
returns
[2018-03-01,2018-03-02)
which means the only date inclusive of this range is 2018-03-01.
Setting Up the Problem: Creating a Travel Scheduler
This guide will assume you have a glancing familiarity with the range functions available in PostgreSQL, as well as a running a PostgreSQL 10 database.
Creating a Table
Let's create a table to show when travel is booked that also prevents double booking. This can be accomplished with the following code:
CREATE TABLE travels (
id int GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
travel_dates daterange NOT NULL,
EXCLUDE USING spgist (travel_dates WITH &&)
);
If you are not running PostgreSQL 10, the equivalent would be:
CREATE TABLE travels (
id serial PRIMARY KEY,
travel_dates daterange NOT NULL,
EXCLUDE USING spgist (travel_dates WITH &&)
);
The column to store the travel dates is named travel_dates and is of type daterange all the dates that cannot be booked for travel.
Notice at the end of the table definition, there is this line:
EXCLUDE USING spgist (travel_dates WITH &&)
This is an exclusion constraint, which uses a condition to prevent duplicate rows from existing in a table. In this case, we specified that we don't want two rows to have overlapping (&&) travel_dates, thus we should never double-book our travel. An exclusion constraint requires an index, and in this case I chose to use an SP-GiST index. Range types support both GiST and SP-GiST indexes, and as much as I would like to discuss the differences and how to choose, this is a topic outside the scope of this post.
Adding Data
Let's insert some travel for March 2018:
INSERT INTO travels (travel_dates)
VALUES
(daterange('2018-03-02', '2018-03-02', '[]')),
(daterange('2018-03-06', '2018-03-09', '[]')),
(daterange('2018-03-11', '2018-03-12', '[]')),
(daterange('2018-03-16', '2018-03-17', '[]')),
(daterange('2018-03-25', '2018-03-27', '[]'));
In other words, the travel dates are:
- March 2
- March 6 - March 9
- March 11 - March 12
- March 16 - March 17
- March 25 - March 27
What happens if we try to add a trip from Mar 9 - Mar 11?
INSERT INTO travels (travel_dates)
VALUES (daterange('2018-03-09', '2018-03-11', '[]'));
We receive the following message:
**ERROR: conflicting key value violates exclusion constraint "travels_travel_dates_excl"**
**DETAIL: Key (travel_dates)=([2018-03-09,2018-03-12)) conflicts with existing key
(travel_dates)=([2018-03-06,2018-03-10)).**
The exclusion constraint works: we are prevented from double-booking! Also note the output of the error message: by default PostgreSQL outputs discrete ranges (e.g. dates, integers) in the inclusive-exclusive format. The March 6 - March 9 trip is displayed as [2018-03-06, 2018-03-10) but it is equivalent to [2018-03-06, 2018-03-09].
Determining if Dates are Available
A useful part of our travel log is to determine whether or not we can travel on certain dates. For example, if I wanted to see if I could travel between March 9 and March 11, 2018, I would try to find if any overlapping travel dates existing using this query:
SELECT NOT EXISTS (
SELECT 1
FROM travels
WHERE travels.travel_dates && daterange('2018-03-09', '2018-03-11', '[]')
LIMIT 1
);
The EXISTS function returns TRUE if the subquery returns any rows. In the subquery, there are a couple of "tricks" to help optimize performance:
- EXISTS cares about how many rows are turned. It does not matter which columns, if any, are returned, so we can use a constant of "1" to aid performance.
- We only need one row to be returned for EXISTS to return TRUE, so we can use the LIMIT 1 clause to short-circuit out of the query as soon as a row is found.
Using the above data, the result of this query is FALSE - we cannot book travel during March 9 - March 11 because of the March 6 - March 9 trip (which we know from the previous section). If we try the same query for a March 13 - March 14 trip:
SELECT NOT EXISTS (
SELECT 1
FROM travels
WHERE travels.travel_dates && daterange('2018-03-13', '2018-03-14', '[]')
LIMIT 1
);
we will get a result of TRUE.
As a bonus, let's turn the above query into a function, because it seems like something we could end up calling a lot:
CREATE OR REPLACE FUNCTION travels_can_book_travel_dates(daterange)
RETURNS boolean
AS $$
SELECT NOT EXISTS (
SELECT 1
FROM travels
WHERE travels.travel_dates && $1
LIMIT 1
);
$$ LANGUAGE SQL STABLE;
which simplifies the above queries to:
SELECT travels_can_book_travel_dates(daterange('2018-03-09', '2018-03-11', '[]'));
The Problem: Looking at Overall Availability
So far, we have looked only at when travel dates are unavailable. What if we want to see all dates that are available to travel in March 2018?
First, it helps to know that you can add and subtract ranges, for example, adding these two ranges:
SELECT daterange('2018-03-04', '2018-03-05') + daterange('2018-03-05', '2018-03-06');
returns:
[2018-03-04,2018-03-06)
and subtracting these two ranges:
SELECT daterange('2018-03-04', '2018-03-06') - daterange('2018-03-04', '2018-03-05');
returns:
[2018-03-05,2018-03-06)
Therefore, if we wanted to see all the dates that are not booked in March, we could take the range daterange('2018-03-01', '2018-03-31', '[]') and subtract out all of the booked travel dates - right?
As of PostgreSQL 10, the sum aggregate function does not support range types. To see why this is a challenge, let's try subtracting our first booked date, March 2, from all available dates in March 2018:
SELECT daterange('2018-03-01', '2018-03-31', '[]') - daterange('2018-03-02', '2018-03-02', '[]');
yields:
**ERROR: result of range difference would not be contiguous**
Subtracting daterange('2018-03-02', '2018-03-02', '[]') from daterange('2018-03-01', '2018-03-31', '[]') should yield two separate ranges: daterange('2018-03-01', '2018-03-01', '[]') and daterange('2018-03-03', '2018-03-31', '[]'). As of PostgreSQL 10, this functionality with the subtraction operator is not supported.
However, thanks to the feature-richness of PostgreSQL, we can develop a solution right now: all it takes is some SQL.
The Solution: Recursion
In PostgreSQL 8.4, PostgreSQL introduced the common table expressions (aka "WITH" queries) that also enables recursive queries. There are full-length talks just on how to write recursive queries with PostgreSQL, but for this case, we will just look at the solution to the problem at hand.
To understand the query were are about to write, it helps to visualize what needs to be done. Our goal is to find all remaining travel dates for the month of March. Visually, that should look something like this:
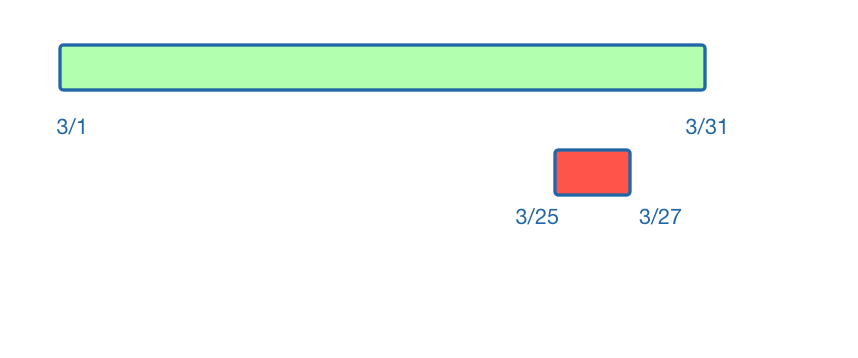
 Let's look at one of the booked travel dates: March 25 - March 27. From the image below, you can see that it does overlap with all available dates in March.
Let's look at one of the booked travel dates: March 25 - March 27. From the image below, you can see that it does overlap with all available dates in March.
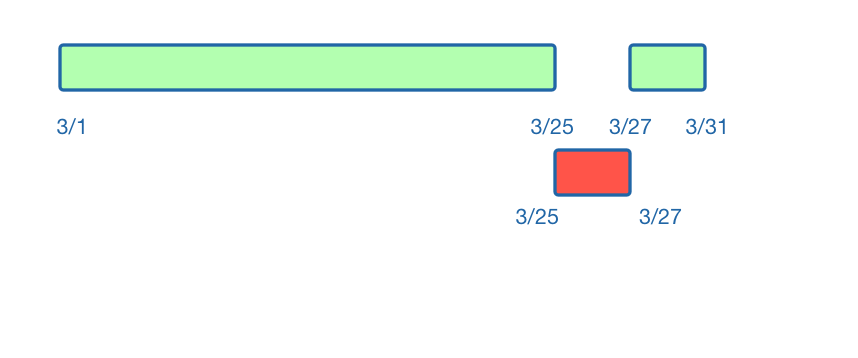
 Effectively, what we need to do is split up the available dates. In this case, we will take the known travel dates Using the known travel dates to create two blocks of available travel dates: March 1 - March 25, and March 27 - March 31.
Effectively, what we need to do is split up the available dates. In this case, we will take the known travel dates Using the known travel dates to create two blocks of available travel dates: March 1 - March 25, and March 27 - March 31.
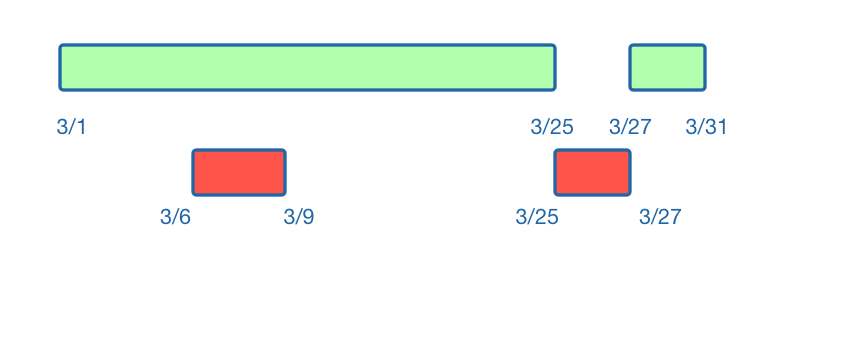
 Now, let's take another set of travel dates: March 6 - March 9. We can see that these dates overlap with the March 1 - March 25 range.
Now, let's take another set of travel dates: March 6 - March 9. We can see that these dates overlap with the March 1 - March 25 range.
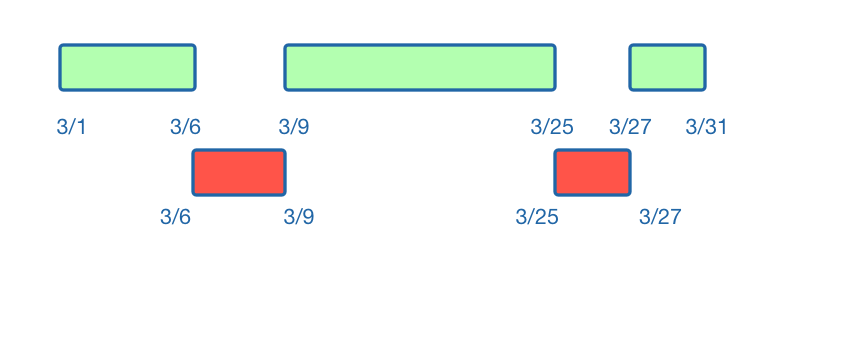
 The process is the same as before: we can use the known travel dates to split up the available dates, and create two available ranges of March 1 - March 6, and March 9 - March 25.
The process is the same as before: we can use the known travel dates to split up the available dates, and create two available ranges of March 1 - March 6, and March 9 - March 25.
 Looks easy enough! So how do we turn this into SQL? A recursive query needs to ensure there is a base case and that case that allows the query to terminate. Our base case will be the horizon we are looking over for availability: March 1 - March 31.
Looks easy enough! So how do we turn this into SQL? A recursive query needs to ensure there is a base case and that case that allows the query to terminate. Our base case will be the horizon we are looking over for availability: March 1 - March 31.
WITH RECURSIVE calendar AS (
SELECT
daterange('2018-03-01', '2018-04-01') AS left,
daterange('2018-03-01', '2018-04-01') AS center,
daterange('2018-03-01', '2018-04-01') AS right
UNION
SELECT
CASE travels.travel_dates && calendar.left
WHEN TRUE THEN daterange(lower(calendar.left), lower(travels.travel_dates * calendar.left))
ELSE daterange(lower(calendar.right), lower(travels.travel_dates * calendar.right))
END AS left,
CASE travels.travel_dates && calendar.left
WHEN TRUE THEN travels.travel_dates * calendar.left
ELSE travels.travel_dates * calendar.right
END AS center,
CASE travels.travel_dates && calendar.right
WHEN TRUE THEN daterange(upper(travels.travel_dates * calendar.right), upper(calendar.right))
ELSE daterange(upper(travels.travel_dates * calendar.left), upper(calendar.left))
END AS right
FROM calendar
JOIN travels ON
travels.travel_dates && daterange('2018-03-01', '2018-04-01') AND
travels.travel_dates <> calendar.center AND (
travels.travel_dates && calendar.left OR
travels.travel_dates && calendar.right
)
)
SELECT *
FROM (
SELECT
a.left AS available_dates
FROM calendar a
LEFT OUTER JOIN calendar b ON
a.left <> b.left AND
a.left @> b.left
GROUP BY a.left
HAVING NOT bool_or(COALESCE(a.left @> b.left, FALSE))
UNION
SELECT a.center AS available_dates
FROM calendar a
LEFT OUTER JOIN calendar b ON
a.center <> b.center AND
a.center @> b.center
GROUP BY a.center
HAVING NOT bool_or(COALESCE(a.center @> b.center, FALSE))
UNION
SELECT
a.right AS available_dates
FROM calendar a
LEFT OUTER JOIN calendar b ON
a.right <> b.right AND
a.right @> b.right
GROUP BY a.right
HAVING NOT bool_or(COALESCE(a.right @> b.right, FALSE))
) a
WHERE NOT isempty(a.available_dates);
First, note the RECURSIVE modifier at the beginning of the query: this tells the PostgreSQL query planner that it could expect a recursive CTE, though in actuality there may not be one. We setup three ranges to track: left, center, and right. These are similar to the ranges illustrated in the pictures above: left and right track the available date ranges as they are split up, while center tracks the existing unavailable ranges.
To connect the base case with the recursive part of the query, we use the UNION because it will eliminate duplicate rows from how the ranges are split up in the recursive steps. The SELECT list logic performs the available travel date range split similar to the illustrations. The WHERE checks to see if there are any remaining overlaps between available ranges (in left and right) with the unavailable travel_dates in the travels table for our horizon (March 1 - March 31). The condition travels.travel_dates <> calendar.center ensures we do not loop infinitely: a row in our recursive set that has a center column travel_dates range, then we know we have already split up that range.
Finally, we need to use aggregation to find the best fit available dates. As mentioned earlier, all of the available date ranges will be in the left and right columns. If you look at the raw data generated (WITH RECURSIVE calendar AS (...) SELECT * FROM calendar;) you will see that it appears there are extra rows. Upon closer inspection, these extra rows are ranges of available dates that can fully encompass other ranges within the data set. The @> operator allows you to detect if the range on the left side of the operator can fully encompass the range on its right. We can use this to find the largest, non-overlapping available ranges.
Finally, we perform a UNION between the left and right ranges, and finally return all the available travel dates in March in order:
available_dates
-------------------------
[2018-03-01,2018-03-02)
[2018-03-03,2018-03-06)
[2018-03-10,2018-03-11)
[2018-03-13,2018-03-16)
[2018-03-18,2018-03-25)
[2018-03-28,2018-04-01)
Excellent! And because this is a query we could end up using often, here is the above query parameterized in a function:
CREATE OR REPLACE FUNCTION travels_get_available_dates(daterange)
RETURNS TABLE(available_dates daterange)
AS $$
WITH RECURSIVE calendar AS (
SELECT
$1 AS left,
$1 AS center,
$1 AS right
UNION
SELECT
CASE travels.travel_dates && calendar.left
WHEN TRUE THEN daterange(lower(calendar.left), lower(travels.travel_dates * calendar.left))
ELSE daterange(lower(calendar.right), lower(travels.travel_dates * calendar.right))
END AS left,
CASE travels.travel_dates && calendar.left
WHEN TRUE THEN travels.travel_dates * calendar.left
ELSE travels.travel_dates * calendar.right
END AS center,
CASE travels.travel_dates && calendar.right
WHEN TRUE THEN daterange(upper(travels.travel_dates * calendar.right), upper(calendar.right))
ELSE daterange(upper(travels.travel_dates * calendar.left), upper(calendar.left))
END AS right
FROM calendar
JOIN travels ON
travels.travel_dates && $1 AND
travels.travel_dates <> calendar.center AND (
travels.travel_dates && calendar.left OR
travels.travel_dates && calendar.right
)
)
SELECT *
FROM (
SELECT
a.left AS available_dates
FROM calendar a
LEFT OUTER JOIN calendar b ON
a.left <> b.left AND
a.left @> b.left
GROUP BY a.left
HAVING NOT bool_or(COALESCE(a.left @> b.left, FALSE))
UNION
SELECT a.center AS available_dates
FROM calendar a
LEFT OUTER JOIN calendar b ON
a.center <> b.center AND
a.center @> b.center
GROUP BY a.center
HAVING NOT bool_or(COALESCE(a.center @> b.center, FALSE))
UNION
SELECT
a.right AS available_dates
FROM calendar a
LEFT OUTER JOIN calendar b ON
a.right <> b.right AND
a.right @> b.right
GROUP BY a.right
HAVING NOT bool_or(COALESCE(a.right @> b.right, FALSE))
) a
WHERE NOT isempty(a.available_dates)
$$ LANGUAGE SQL STABLE;
Conclusion and Follow-Ups
PostgreSQL's built in data types and functionality allows you to perform some very powerful lookups and manipulations out-of-the-box. In a real calendaring system, though, there are often a lot of other factors to consider, such as additional conditions around availability as well as system performance. You may decide that your system needs to store both available and booked travel dates: it may add more data to disk, but allow your users to perform efficient searches.
The above query is a building block into more complex availability systems, but depending on your needs and for performance considerations, you may consider using a PL language, e.g. PL/pgSQL, PL/Python, PL/R, etc. to perform the lookup iteratively.
Your best bet is to try experiment and try it out: PostgreSQL gives you a lot of options in how you can architect your system!
Related Articles
- Hacking the Postgres Statistics Tables for Faster Queries
13 min read
- OpenTelemetry Observability in Crunchy Postgres for Kubernetes
8 min read
- Creating Histograms with Postgres
10 min read
- Introducing Crunchy Postgres for Kubernetes 5.8: OpenTelemetry, API enhancements, UBI-9 and More
4 min read
- Crunchy Data Warehouse: Postgres with Iceberg Available for Kubernetes and On-premises
6 min read