Latest Articles
Scheduled PostgreSQL Backups and Retention Policies with Kubernetes
Jonathan S. Katz
5 min readMore by this author
It is important (understatement) that you take regularly scheduled backups of your PostgreSQL system as well as manage how many backups you have, which is known as "backup retention." These best practices ensure that you always have a recent backup of your database system to recover from in the event of a disaster (or use to clone a new copy of your database) and that you don't run out of storage on your backup device or blow up your object storage bill (true story from a previous life, I had a year's worth of nightly backups on S3 when it should have been 21 days...though it was not as expensive as I thought. I also wasn't using pgBackRest which would have caught the error).
When I've given various talks on PostgreSQL and ask the question "do you take regular backups of your production systems," I don't see as many hands raised as I would like (and I'll also use this as an opportunity to say that having a replica is not a backup). However, if you are running PostgreSQL on Kubernetes using the PostgreSQL Operator, with a few commands, the answer to this question is "Yes!"
The PostgreSQL Operator uses the aforementioned open source pgBackRest backup and restore utility to help you manage backups, and includes the ability to schedule regular backups and set retention policies. Even better, as of the release of PostgreSQL Operator 4.2, pgBackRest is enabled by default, which the PostgreSQL Operator leverages to automate a few convenient behaviors, including scheduling full, differential, and incremental backups and setting retention policies!
Let's learn how we can use these features and the PostgreSQL Operator to schedule regular backups and set an appropriate retention policy with the PostgreSQL Operator.
Scheduling Backups
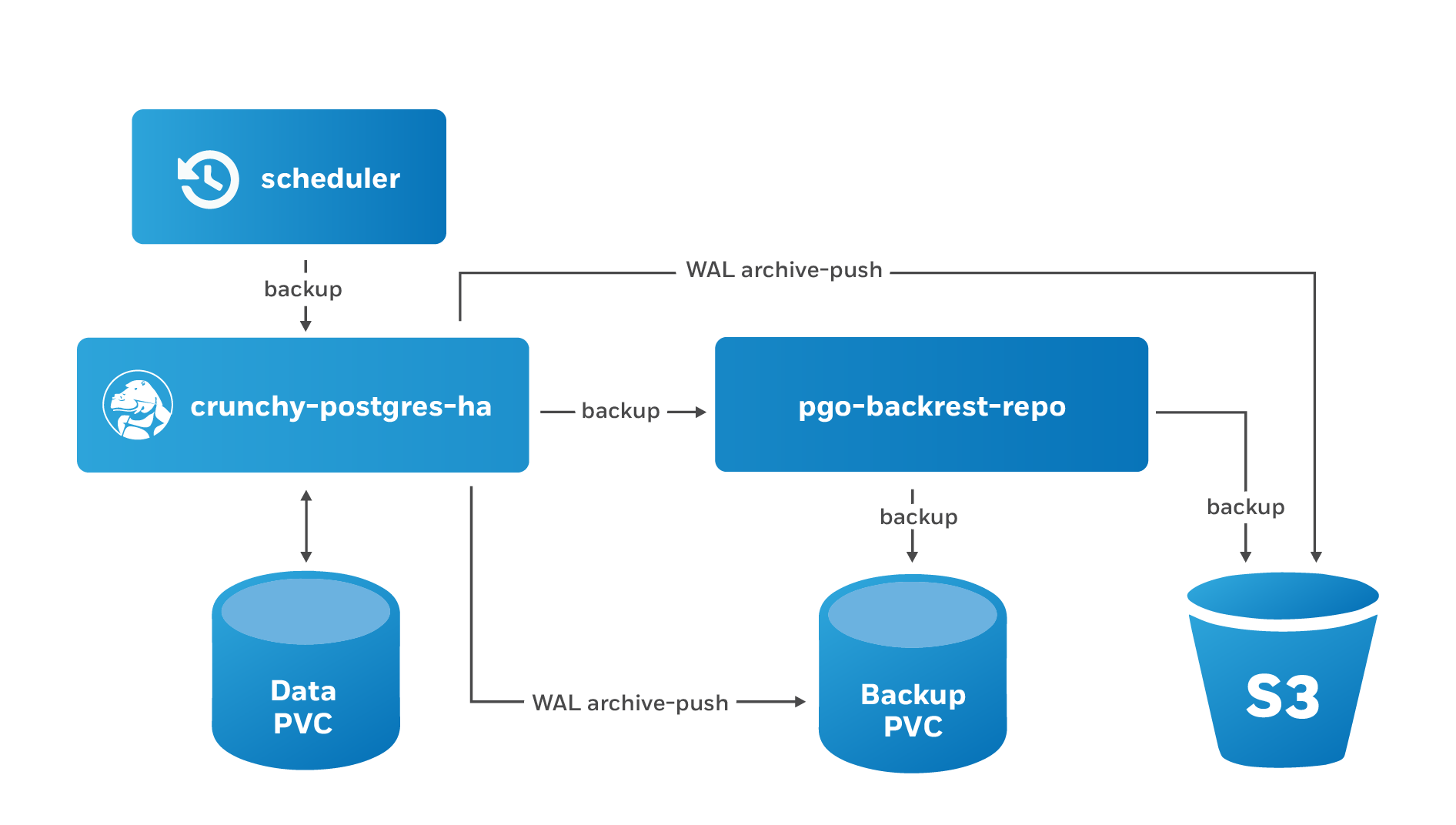 It's generally a good idea to automate the scheduling of backups: you don't want to forget to take a backup, and then have something bad happen. The PostgreSQL Operator allows for scheduling backups through its scheduling sidecar, pictured below:
It's generally a good idea to automate the scheduling of backups: you don't want to forget to take a backup, and then have something bad happen. The PostgreSQL Operator allows for scheduling backups through its scheduling sidecar, pictured below:
The PostgreSQL Operator Scheduler is essentially a cron server that will run jobs that it is specified. Schedule commands use the cron syntax to set up scheduled tasks.
Let's see how it works by creating a backup that we take once a day at 1am. First, after ensuring you've deployed the PostgreSQL Operator, let's create a new PostgreSQL cluster:
pgo create cluster hippo
This may take a few moments depending on your environment.
To create the scheduled task to run a full backup for the hippo cluster to occur at 1am, you can use the pgo create schedule command like so:
pgo create schedule hippo --schedule="0 1 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=full
What do each of these flags mean mean?
- --schedule takes cron-style arguments to indicate when the job should be run.
- --schedule-type indicates the type of scheduled job that should be run, which in this case is pgbackrest.
- --pgbackrest-backup-type=full tells the schedule to take a full backup of the PostgreSQL database. The options are full, incr, and diff for full, incremental, and differential backups respectively.
If you want to see your scheduled job run sooner, feel free to tweak the arguments so you can see that it works!
As another example, let's say we want to take an incremental backup every 3 hours. We could set up this scheduled task with the following command:
pgo create schedule hippo --schedule="0 */3 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=incr
Easy!
Setting Up a Backup Retention Policy
Now, the issue with the above commands is that our backup repository size will keep on growing until we run out of disk (or your cloud object storage bills become too large). This is where setting a retention policy is helpful: you can regulate how many backups you keep to better manage your backup disk utilization.
The pgo create schedule command comes with an additional flag called --schedule-opts that allows you to pass in almost any of the command-line options that are supported by the pgBackRest backup command. Knowing this, if we want to set a retention policy on our full backups, we can leverage the --repo-retention-full flag. Note that with the PostgreSQL Operator, you will specify this using --repo1-retention-full.
For example, a typical backup retention policy is to retain 21 days worth of backups. Using our nightly 1am full backup from earlier, we can set up this kind of policy by running the following command:
pgo create schedule hippo --schedule="0 1 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=full \
--schedule-opts="--repo1-retention-full=21"
Notice how we pass in the additional commands for the pgBackRest backup command in the --schedule-opts flag.
And that's it! You now can not only schedule backups with the PostgreSQL Operator, you can even ensure you only keep the ones that you want!
Conclusion
It is necessary that you take backups of any of your PostgreSQL clusters in production, for the sake of your users and for your own peace of mind. Importantly, it's important to take safe and correct backups of your clusters too, which is one reason why the PostgreSQL Operator uses pgBackRest. Automatically taking backups and managing your backup retention policies helps you to ensure you are operating a healthy production PostgreSQL system.
Related Articles
- Logical replication from Postgres to Iceberg
4 min read
- Hacking the Postgres Statistics Tables for Faster Queries
13 min read
- OpenTelemetry Observability in Crunchy Postgres for Kubernetes
8 min read
- Creating Histograms with Postgres
10 min read
- Introducing Crunchy Postgres for Kubernetes 5.8: OpenTelemetry, API enhancements, UBI-9 and More
4 min read