You followed all the best practices, your sales dates are stored in perfect timestamp format …. but now you need to get reports by day, week, quarters, and months. You need to roll up sales data in easy to view reports. Do you need a BI tool? Not yet actually. Your Postgres database has hundreds of functions that let you query data analytics by date. By using some good old fashioned SQL - you have powerful analysis and business intelligence with date details on any data set.
In this post, I’ll walk through some of the key functions for date queries and rollups. For a summary of the best ways to store date and time in Postgres, see Working with Time in Postgres.
Postgres date intervals
The interval is a data type that can modify other time related data can be
used in time and date queries. Interval is super handy and the first place you
can go to quickly summarize data by date.
Here’s a sample query that will do a total of orders for the last 90 days.
SELECT SUM(total_amount)
FROM orders
WHERE order_date >= NOW() - INTERVAL '90 days';
Interval can be written two ways, also as a cast. This is essentially the exact same query.
SELECT SUM(total_amount)
FROM orders
WHERE order_date >= NOW() - '90 days'::interval;
You can also use intervals for more complicated questions. You can do time ranges and you can compare more than one interval.
In this sample query, you can use a CASE statement to create more than one
interval range. The CASE statement in SQL is used to perform conditional
logic within queries, similar to an if-else structure in programming. In the
query below, it's being used to categorize orders into different time ranges
(e.g., "30-60 days ago", "60-90 days ago").
SELECT
CASE
WHEN order_date BETWEEN (NOW() - INTERVAL '60 days') AND (NOW() - INTERVAL '30 days')
THEN '30-60 days ago'
WHEN order_date BETWEEN (NOW() - INTERVAL '90 days') AND (NOW() - INTERVAL '60 days')
THEN '60-90 days ago'
END AS date_range,
COUNT(*) AS total_orders,
SUM(total_amount) AS total_sales
FROM orders
WHERE order_date BETWEEN (NOW() - INTERVAL '90 days') AND (NOW() - INTERVAL '30 days')
GROUP BY date_range
ORDER BY date_range;
date_trunc - easy date rollups for Postgres
Interval is a pretty simple idea but once you go beyond a couple basic
summaries, most data analytics with dates will take advantage of the
date_trunc function. Honestly, I hardly ever use interval, my brain just
doesn't work like that.
At a glance, date_trunc’s name might indicate that its about formatting - but stick with me for these examples, it is so much more. date_trunc is an essential part of the query toolkit when working with analytics. date_trunc lets you slice and dice your data by any date, viewing exactly the things you need to create insightful summary analytics.
Here’s a sample query that shows each individual month, the number of orders, and the total order sales.
SELECT
date_trunc('month', order_date) AS month,
COUNT(*) AS total_orders,
SUM(total_amount) AS monthly_total
FROM
orders
GROUP BY
date_trunc('month', order_date)
ORDER BY
month;
month | total_orders | monthly_total
---------------------+--------------+---------------
2024-08-01 00:00:00 | 11 | 2699.82
2024-09-01 00:00:00 | 39 | 8439.41
(2 rows)
The GROUP BY makes sure that each row collects the date_trunc totals. When you
use date_trunc in combination with GROUP BY, you're aggregating your results
based on the truncated date. This lets you summarize data (like counts, sums,
averages) for each unique truncated date.
Summaries by day
SELECT
date_trunc('day', order_date) AS day,
SUM(total_amount) AS daily_total
FROM
orders
GROUP BY
date_trunc('day', order_date)
ORDER BY
day;
day | daily_total
---------------------+-------------
2024-08-21 00:00:00 | 349.98
2024-08-22 00:00:00 | 899.98
2024-08-23 00:00:00 | 34.98
Summaries by week
SELECT
date_trunc('week', order_date) AS week,
SUM(total_amount) AS weekly_total
FROM
orders
GROUP BY
date_trunc('week', order_date)
ORDER BY
week;
week | weekly_total
---------------------+-------------
2024-08-19 00:00:00 | 1524.92
2024-08-26 00:00:00 | 2854.84
2024-09-02 00:00:00 | 4309.72
Quarters
Postgres will give you quarters with date_trunc, starting with Jan 1, April 1, July 1, and Oct 1.
SELECT
date_trunc('quarter', order_date) AS quarter,
SUM(total_amount) AS weekly_total
FROM
orders
GROUP BY
date_trunc('quarter', order_date)
ORDER BY
quarter;
2022-01-01 00:00:00+00 | 313872.84
2022-04-01 00:00:00+00 | 270162.38
2022-07-01 00:00:00+00 | 295197.26
2022-10-01 00:00:00+00 | 283051.73
date_trunc CTEs are a super power
If you have a simple example, like the one above, a basic date_trunc query is a good idea. Beyond that, it’s often a good idea to work with date_trunc inside a CTE. There’s a few reasons for this:
- Performance: If you're using date_trunc repeatedly across a large dataset, using a CTE might allow PostgreSQL to optimize better, as it can calculate the result once and reuse it.
- Readability: Splitting a query into manageable pieces makes it easier to read, maintain, and reuse.
Here’s a sample query using date_trunc by month that calculates calculate total sales for each month and then also calculates month-over-month sales and percentage change:
WITH monthly_sales AS (
SELECT
date_trunc('month', order_date) AS month,
SUM(total_amount) AS total_sales
FROM orders
WHERE order_date >= NOW() - INTERVAL '6 months' -- Filter for the last 6 months
GROUP BY date_trunc('month', order_date) -- Group by the truncated month
ORDER BY month
),
sales_with_change AS (
SELECT
month,
total_sales,
LAG(total_sales, 1) OVER (ORDER BY month) AS previous_month_sales, -- Get the sales of the previous month
(total_sales - LAG(total_sales, 1) OVER (ORDER BY month)) AS sales_change,
CASE
WHEN LAG(total_sales, 1) OVER (ORDER BY month) IS NOT NULL THEN
((total_sales - LAG(total_sales, 1) OVER (ORDER BY month)) / LAG(total_sales, 1) OVER (ORDER BY month)) * 100
ELSE
NULL
END AS percentage_change
FROM monthly_sales
)
SELECT
month,
total_sales,
previous_month_sales,
sales_change,
percentage_change
FROM sales_with_change
ORDER BY month DESC;
-[ RECORD 1 ]--------+-------------------------
month | 2024-10-01 00:00:00+00
total_sales | 64685.65
previous_month_sales | 103188.90
sales_change | -38503.25
percentage_change | -37.31336413121954008600
-[ RECORD 2 ]--------+-------------------------
month | 2024-09-01 00:00:00+00
total_sales | 103188.90
previous_month_sales | 88512.52
sales_change | 14676.38
percentage_change | 16.58113451068843142200
Customize your output date formatting with to_char
If you need reports output in a specific format for use in another system or just readability, you can embed the to_char function into any of the things we’ve already talked about.
Formatting months
So for example, to change the way a month look, with just the month and year in our monthly date_trunc query:
SELECT
to_char(date_trunc('month', order_date), 'FMMonth YYYY') AS formatted_month,
COUNT(*) AS total_orders,
SUM(total_amount) AS monthly_total
FROM
orders
GROUP BY
date_trunc('month', order_date)
ORDER BY
date_trunc('month', order_date);
formatted_month | total_orders | monthly_total
-----------------+--------------+---------------
August 2024 | 11 | 2699.82
September 2024 | 39 | 8439.41
A popular date display for text can be done like this:
SELECT TO_CHAR(NOW():: DATE, 'Mon dd, yyyy');
Fiscal quarters
Renaming quarters, can be done with a to_char callout like this:
to_char(date_trunc('quarter', order_date), '"Q"Q-YYYY'):
SELECT
to_char(date_trunc('quarter', order_date), '"Q"Q-YYYY') AS formatted_quarter,
SUM(total_amount) AS total_amount
FROM
orders
GROUP BY
date_trunc('quarter', order_date)
ORDER BY
date_trunc('quarter', order_date);
formatted_quarter | total_amount
-------------------+--------------
Q3-2024 | 11139.23
Superpowered Group By
If you’ve been paying attention to the above examples, you’ve seen a lot of
GROUP BY. Postgres has some even fancier group by functions for working with
this kind of data that can be really helpful for analytics with dates.
GROUP BY ROLLUP
ROLLUP is a really handy function for analytics reporting. Rollup will give
you big batches of things, including things with null values. If you want to do
a quick survey of your products or data by certain categories, rollup is a great
tool. You can combine that with our date_trunc to get a rollup of product
categories sold by date.
SELECT
to_char(date_trunc('month', order_date), 'FMMonth YYYY') AS month,
category,
COUNT(*) AS total_orders,
SUM(total_amount) AS total_amount
FROM
orders
GROUP BY
ROLLUP (date_trunc('month', order_date), category)
ORDER BY
date_trunc('month', order_date), category;
month | category | total_orders | total_amount
----------------+-------------+--------------+--------------
October 2021 | Books | 3 | 2375.73
October 2021 | Clothing | 18 | 13770.09
October 2021 | Computers | 17 | 13005.87
October 2021 | Electronics | 25 | 16358.96
October 2021 | | 63 | 45510.65
GROUP BY CUBE
The cube function takes this one step further and does subtotals and grand totals across all the dimensions you’ve queried. So very similar to ROLLUP, we can look at both dates and categories of sales.
SELECT
to_char(date_trunc('month', order_date), 'FMMonth YYYY') AS month,
category,
COUNT(*) AS total_orders,
SUM(total_amount) AS total_amount
FROM
orders
GROUP BY
CUBE (date_trunc('month', order_date), category)
ORDER BY
date_trunc('month', order_date), category;
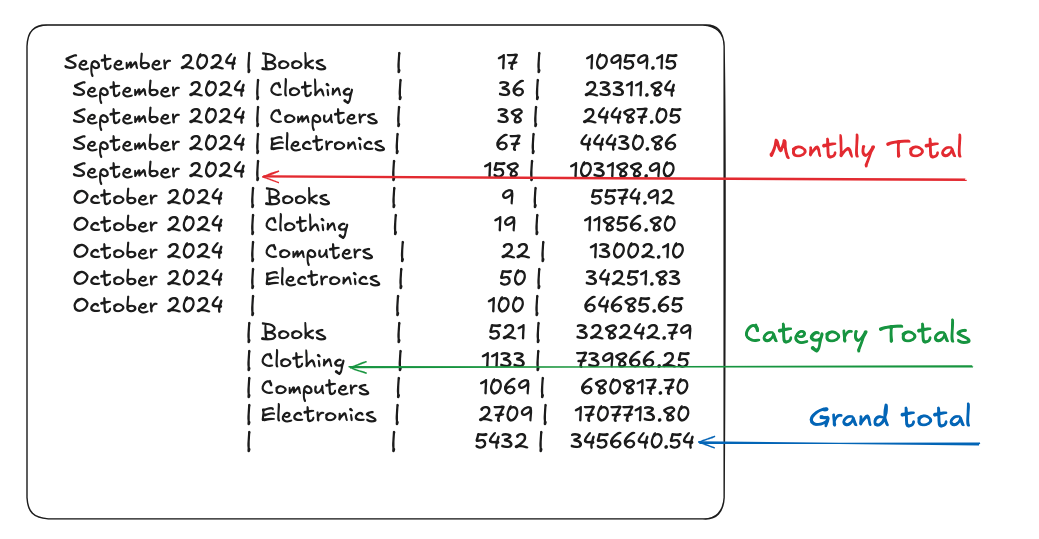
October 2024 | Books | 9 | 5574.92
October 2024 | Clothing | 19 | 11856.80
October 2024 | Computers | 22 | 13002.10
October 2024 | Electronics | 50 | 34251.83
October 2024 | | 100 | 64685.65
| Books | 521 | 328242.79
| Clothing | 1133 | 739866.25
| Computers | 1069 | 680817.70
| Electronics | 2709 | 1707713.80
| | 5432 | 3456640.54
Cube is kind of interesting in that these subtitles aren’t labeled, they have null values representing the totals, like this:
Summary
As you can see, Postgres has you covered for doing reporting and analytics with dates! Tools like Crunchy Bridge for Analytics make it even easier to connect to large data sets, object stores, and data lakes. As more tools like this bring analytical workloads into Postgres and Postgres has the performance to back up the OLAP workloads, I expect more folks will be taking advantage of all the functions that make this so easy.
My quick final notes:
intervals - good for quick query to review the past month or so
date_trunc - totally amazing and can give you individual rows of summary data by day, week, moth, quarter, year, etc
rollups - let you summarize across other attributes or categories, as well as date
cube - uses rollup plus sub and grand totals to_char - can help you with the formatting output into a specific style of date format or text string