SQL makes sense when it's working on a single row, or even when it's aggregating across multiple rows. But what happens when you want to compare between rows of something you've already calculated? Or make groups of data and query those. Enter window functions.
Window functions tend to confuse people - but they’re a pretty awesome tool in SQL for data analytics. The best part is that you don’t need charts, fancy BI tools or AI to get some actionable and useful data for your stakeholders. Window functions let you:
- Calculate running totals
- Provide summary statistics for groups/partitions of data
- Create rankings
- Perform lag/lead analysis, ie comparing two separate sets of data with each other
- Compute moving/rolling averages
In this post, I will show various types of window functions and how they can apply to certain situations. I’m using a super simple ecommerce schema for this to follow along with the kinds of queries I’m going to run with window functions.
The OVER function
The OVER part of the Window function is what creates the window. Annoyingly
the word window appears no where in any of the functions. 😂 Typically the OVER
part is preambled by another function, either an aggregate or mathematical
function. There’s also often a frame, which specifics which rows you’re looking
at like ROWS BETWEEN 6 PRECEDING AND CURRENT ROW.
Window functions vs where clauses
Window functions kind of feel like a where clause at first, since they’re looking at a set of data. But they’re really different. Window functions are more for times when you need to look across sets of data or across groups of data. There are cases where you could use either. In general:
- Use
WHEREclause when you need to filter rows based on a condition. - Use window functions when you need to perform calculations across rows that remain after filtering, without removing any rows from the result set.
Running totals
Here’s a simple place to get started. Let’s ask for orders, customer data, order totals, and then a running total of orders. This will show us our total orders across a date range.
SELECT
SUM(total_amount) OVER (ORDER BY order_date) AS running_total,
order_date,
order_id,
customer_id,
total_amount
FROM
orders
ORDER BY
order_date;
running_total | order_date | order_id | customer_id | total_amount
---------------+---------------------+----------+-------------+--------------
349.98 | 2024-08-21 10:00:00 | 21 | 1 | 349.98
1249.96 | 2024-08-22 11:30:00 | 22 | 2 | 899.98
1284.94 | 2024-08-23 09:15:00 | 23 | 3 | 34.98
1374.93 | 2024-08-24 14:45:00 | 24 | 4 | 89.99
1524.92 | 2024-08-25 08:25:00 | 25 | 5 | 149.99
1589.90 | 2024-08-26 12:05:00 | 26 | 6 | 64.98
1839.88 | 2024-08-27 16:35:00 | 27 | 7 | 249.98
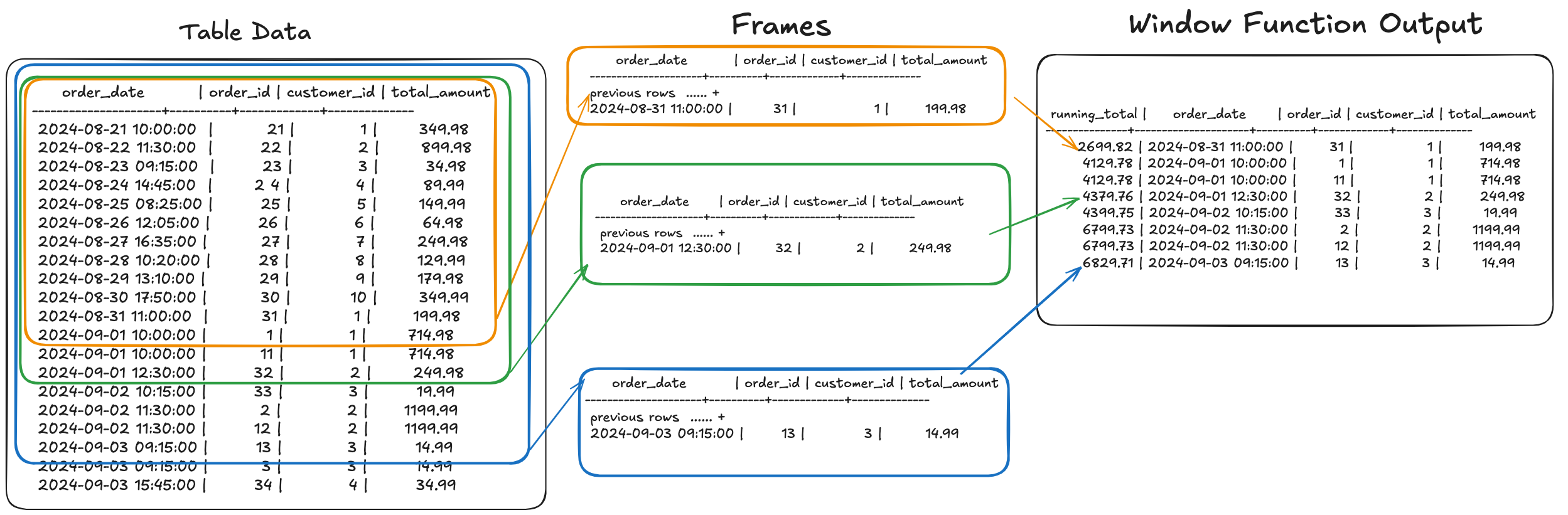
What's happening here is that each frame of data is the existing row plus the
rows before. This sort of does calculations one one slice at a time, which you
might see in the docs called a virtual table. Here's a diagram to get the
general idea of how each frame of data is a set of rows, aggregated by the
function with the SUM OVER.
First and last values
Window functions can look at groups of data, so say a specific customer ID and give you something like their first and last order, total, for your most recent 10 orders.
SELECT
FIRST_VALUE(o.order_date) OVER (PARTITION BY o.customer_id ORDER BY o.order_date) AS first_order_date,
LAST_VALUE(o.order_date) OVER (PARTITION BY o.customer_id ORDER BY o.order_date) AS last_order_date,
o.order_id,
o.customer_id,
o.order_date,
o.total_amount
FROM
orders o
ORDER BY
o.order_date DESC;
first_order_date | last_order_date | order_id | customer_id | order_date | total_amount
---------------------+---------------------+----------+-------------+---------------------+--------------
2024-08-30 17:50:00 | 2024-09-19 18:50:00 | 50 | 10 | 2024-09-19 18:50:00 | 149.98
2024-08-29 13:10:00 | 2024-09-18 14:10:00 | 49 | 9 | 2024-09-18 14:10:00 | 199.98
2024-08-28 10:20:00 | 2024-09-17 11:20:00 | 48 | 8 | 2024-09-17 11:20:00 | 139.99
2024-08-27 16:35:00 | 2024-09-16 17:35:00 | 47 | 7 | 2024-09-16 17:35:00 | 249.98
2024-08-26 12:05:00 | 2024-09-15 13:05:00 | 46 | 6 | 2024-09-15 13:05:00 | 89.98
Using date_trunc GROUP BY CTEs with Window Functions
date_trunc is an incredibly handy Postgres function that summarizes units of
time, hours, days, weeks, month. When combined with a GROUP BY in a CTE, you
can create really easy summary statistics by day, month, week, year, etc.
When you combine the date_trunc GROUP BY partitions with window functions, some pretty magical stuff happens, and you can get readymade summary statistics straight out of your database. In my opinion this is one of the most powerful features of Postgres window functions that really gets you to the next level.
Here’s an example query that starts with a CTE, calling a date_trunc to sum orders by daily totals. The second part of the query, the window function, ranks the sales in descending order with the best day of sales.
WITH DailySales AS (
SELECT
date_trunc('day', o.order_date) AS sales_date,
SUM(o.total_amount) AS daily_total_sales
FROM
orders o
GROUP BY
date_trunc('day', o.order_date)
)
SELECT
sales_date,
daily_total_sales,
RANK() OVER (
ORDER BY daily_total_sales DESC
) AS sales_rank
FROM
DailySales
ORDER BY
sales_rank;
sales_date | daily_total_sales | sales_rank
---------------------+-------------------+------------
2024-09-02 00:00:00 | 2419.97 | 1
2024-09-01 00:00:00 | 1679.94 | 2
2024-08-22 00:00:00 | 899.98 | 3
2024-09-07 00:00:00 | 699.95 | 4
2024-09-10 00:00:00 | 659.96 | 5
2024-09-09 00:00:00 | 499.94 | 6
2024-09-06 00:00:00 | 409.94 | 7
2024-08-30 00:00:00 | 349.99 | 8
I should note that this uses one of the really helpful math function, RANK in
a Window function.
Examples of LAG Analysis
Let’s do more with our date_trunc CTEs. Now that we know we have our data by
day, we can use a window functions to calculate changes between these groups.
For example we could look at the difference in sales from the prior day. In this
example, LAG looks at the sales date and creates a comparison with the
previous day.
WITH DailySales AS (
SELECT
date_trunc('day', o.order_date) AS sales_date,
SUM(o.total_amount) AS daily_total_sales
FROM
orders o
GROUP BY
date_trunc('day', o.order_date)
)
SELECT
sales_date,
daily_total_sales,
LAG(daily_total_sales) OVER (
ORDER BY sales_date
) AS previous_day_sales,
daily_total_sales - LAG(daily_total_sales) OVER (
ORDER BY sales_date
) AS sales_difference
FROM
DailySales
ORDER BY
sales_date;
sales_date | daily_total_sales | previous_day_sales | sales_difference
---------------------+-------------------+--------------------+------------------
2024-08-21 00:00:00 | 349.98 | |
2024-08-22 00:00:00 | 899.98 | 349.98 | 550.00
2024-08-23 00:00:00 | 34.98 | 899.98 | -865.00
2024-08-24 00:00:00 | 89.99 | 34.98 | 55.01
2024-08-25 00:00:00 | 149.99 | 89.99 | 60.00
2024-08-26 00:00:00 | 64.98 | 149.99 | -85.01
LEAD works the same way, looking forward in the data set.
Rolling averages
Using our same day groups we can also make a rolling average. The AVG function
takes an input ROWS BETWEEN 6 PRECEDING AND CURRENT ROW for a rolling 7 day
sales average.
WITH DailySales AS (
SELECT
date_trunc('day', o.order_date) AS sales_date,
SUM(o.total_amount) AS daily_total_sales
FROM
orders o
GROUP BY
date_trunc('day', o.order_date)
)
SELECT
sales_date,
daily_total_sales,
AVG(daily_total_sales) OVER (
ORDER BY sales_date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) AS rolling_average_7_days
FROM
DailySales
ORDER BY
sales_date
LIMIT 10;
sales_date | daily_total_sales | rolling_average_7_days
---------------------+-------------------+------------------------
2024-08-21 00:00:00 | 349.98 | 349.9800000000000000
2024-08-22 00:00:00 | 899.98 | 624.9800000000000000
2024-08-23 00:00:00 | 34.98 | 428.3133333333333333
2024-08-24 00:00:00 | 89.99 | 343.7325000000000000
2024-08-25 00:00:00 | 149.99 | 304.9840000000000000
2024-08-26 00:00:00 | 64.98 | 264.9833333333333333
2024-08-27 00:00:00 | 249.98 | 262.8400000000000000
2024-08-28 00:00:00 | 129.99 | 231.4128571428571429
2024-08-29 00:00:00 | 179.98 | 128.5557142857142857
2024-08-30 00:00:00 | 349.99 | 173.5571428571428571
(10 rows)
NTILES with Window Functions
The NTILE function is a window function in SQL that is used to divide a result
set into a specified number of roughly equal parts, known as tiles or buckets.
By assigning a unique tile number to each row, nitles helps categorize and
analyze data distribution within a dataset. This function is particularly useful
in statistical and financial analysis for understanding how data is distributed
across different segments, identifying trends, and making comparisons between
groups with different characteristics.
For example, using NTILE(4) divides the data into four quartiles, ranking each
row into one of four groups. The descending part here makes sure that quartile 1
is the top quarter and so on.
WITH DailySales AS (
SELECT
date_trunc('day', o.order_date) AS sales_date,
SUM(o.total_amount) AS daily_total_sales
FROM
orders o
GROUP BY
date_trunc('day', o.order_date)
)
SELECT
sales_date,
daily_total_sales,
NTILE(4) OVER (
ORDER BY daily_total_sales DESC
) AS sales_quartile
FROM
DailySales
ORDER BY
sales_date;
sales_date | daily_total_sales | sales_quartile
---------------------+-------------------+----------------
2024-09-06 00:00:00 | 409.94 | 1
2024-08-30 00:00:00 | 349.99 | 1
2024-08-21 00:00:00 | 349.98 | 2
2024-09-08 00:00:00 | 349.96 | 2
Summary
Are there a million other things you can do with Window functions? Yes! Do I think you get the gist here? Also Yes.
Ideal Postgres Window functions with samples I’ve included here:
- Running totals
- Rolling averages
- First and last values
- LAG analysis, looking behind, or LEAD for referring to data ahead
- Ranking
- Partition groups with NTILES
Using with date summary (ie date_trunc GROUP BY) with CTEs and Window
functions is really powerful and will get you quick and easily summary data out
of Postgres.