Disaster Preparedness and Stretched Clusters
Crunchy Postgres for Kubernetes automatically detects problems and self heals by replacing failed instances, Availability Zones or Data Centers.
Robust Disaster Recovery Options
Ensuring the security and availability of your database is a fundamental requirement for businesses today. Crunchy Postgres for Kubernetes comes with disaster recovery configurations enabled by default across all clusters, providing assurance that your database can withstand and recover from failures or disasters.
A well-defined Service Level Objective (SLO) for an application includes critical components like a Recovery Point Objective (RPO), a Recovery Time Objective (RTO), and geographical redundancy. Given the unique requirements each application may have for these components, it's vital to understand their importance.
Crunchy Data for Kubernetes delivers layered protection to meet these objectives effectively. At its core is a default, comprehensive backup strategy, utilizing pgBackRest. This helps facilitate spreading your PostgreSQL cluster across Availability Zones (AZs) or data centers. This configuration guarantees swift, automated recovery from hardware and data center disruptions. Furthermore, it includes automated onsite and off-site backups to highly redundant storage solutions like S3, enhancing geographical redundancy with options for cross regional warm standbys and emergency "break-glass" cold storage recovery. Crunchy Data for Kubernetes also leverages PostgreSQL's inherent replication modes, enabling cross-region "warm" standbys.
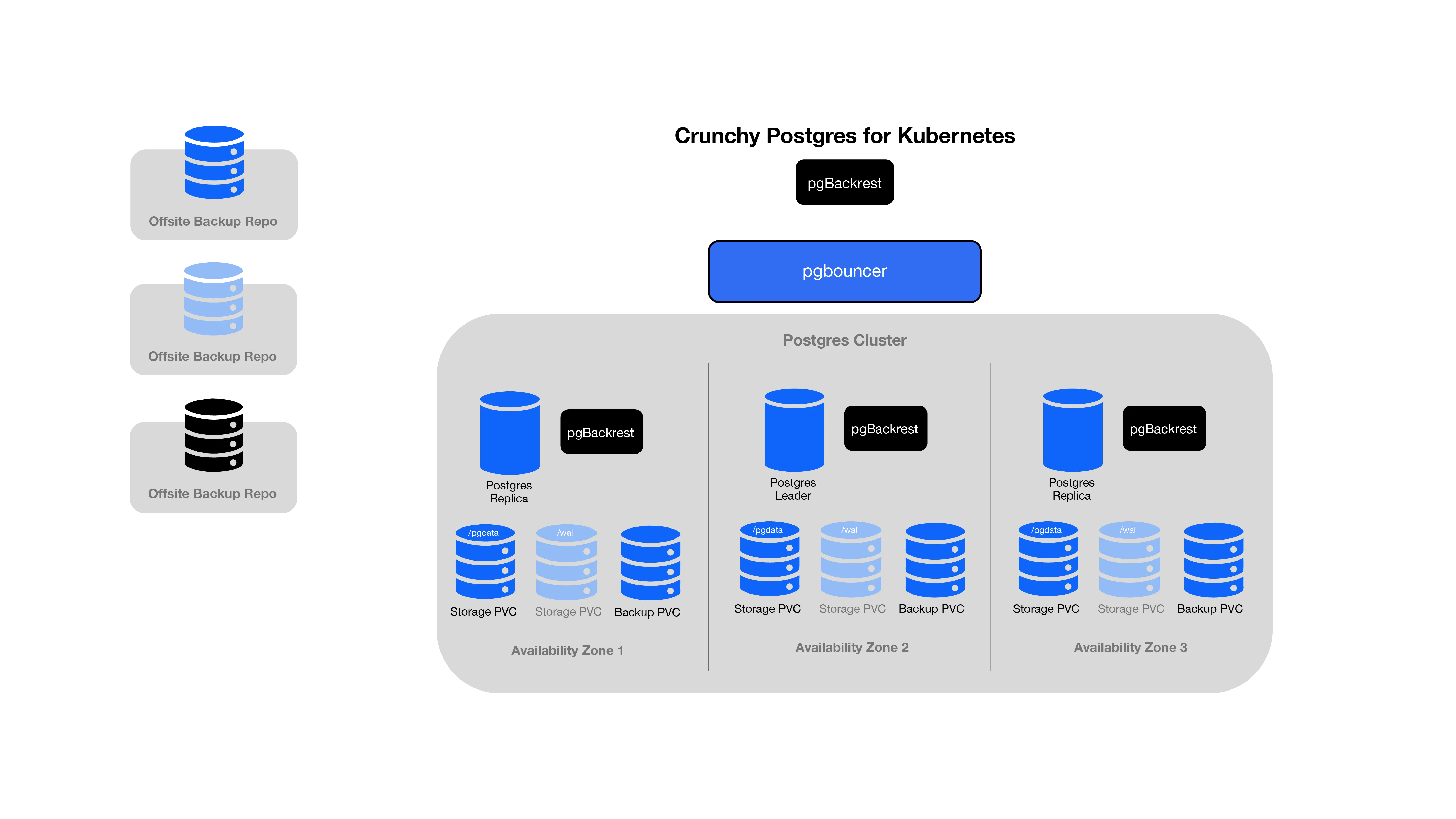
Crunchy Postgres for Kubernetes across multiple Data Centers or Availability Zones (AZs)
Whether running on-premise or in the cloud, your infrastructure architecture can be mapped to improve availability and durability. Stretched clusters within Kubernetes are designed to provide resilient setups that protect against data center failures. In an on-premise setup this could be multiple data centers connected via low latency and high bandwidth connections. In a cloud environment, this setup involves spreading your workload across Availability Zones or AZs for short.
For ensuring your PostgreSQL setup has the needed availability for your business Crunchy Postgres for Kubernetes first and foremost ensures your data stays safe, keeping your applications data accessible even during hardware failures or data center issues.
Crunchy Postgres for Kubernetes spreads your Postgres instances across multiple highly interconnected data, low latency centers or AZs. This ensures that if one data center experiences any problems, your data remains accessible and your applications continue running smoothly.
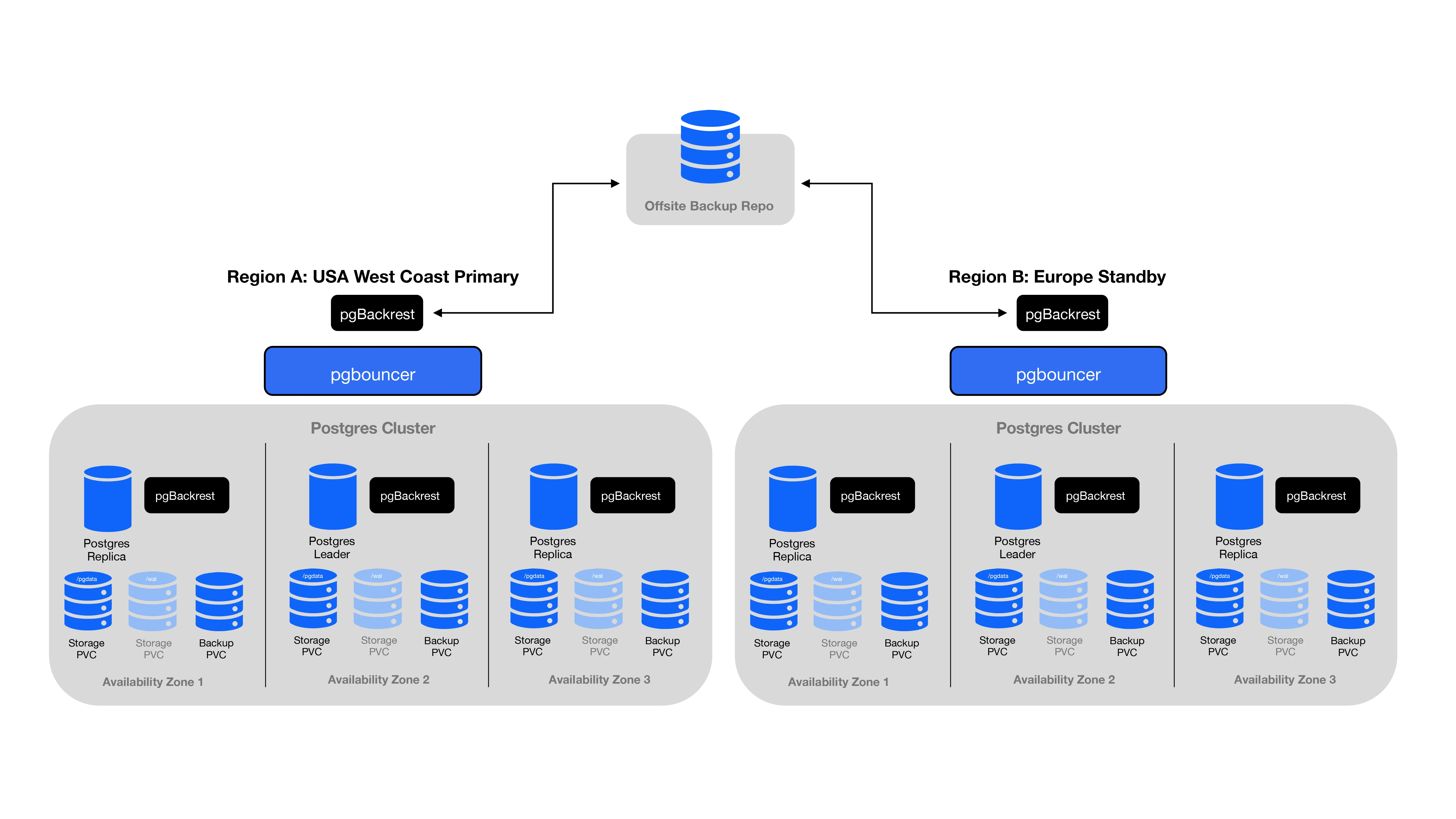
Regional failover
When running mission critical applications, one method to ensure quick mitigation of issues that could impact an entire geographic region is to have a standby running in a different geographic location. For example, you could have a primary datacenter in the West Coast of the United States, and a warm standby in Europe. If any issue impacted access to the primary site, you could fail over to the warm standby in Europe.
This technique can protect against vendor wide outages as well - you could have your primary databases hosted on your own hardware, or in your primary cloud vendor. Your warm standby could be in a different cloud vendor in addition to being geographically separated.
This can also allow you to ease migration between cloud vendors, or between your own hardware and cloud vendors.
Crunchy Postgres for Kubernetes facilitates advanced regional or cross-cloud failover capabilities. This enables data replication across kubernetes clusters in various geographic locations, cloud providers, or a combination of cloud and on-premise environments. By doing so, it enables uninterrupted data accessibility, even in the event of regional disruptions, offering a robust safeguard against potential outages.
Selecting Crunchy Data as our PostgreSQL vendor became clear upon evaluating the Crunchy Postgres Operator. The Postgres Operator hit on all the major deliverables we were looking for in being able to deploy PostgreSQL as a service to our stakeholders. Seamless upgrades, high availability, simple provisioning, backups, and DR options are some of the things that enabled us to offer a well-rounded and versatile service that included developing supplemental automations to simplify the consumption and onboarding process for our custom apps and enterprise software that uses an external PG across the enterprise.Kris Reese, Team Lead, WWT
Automatic multi-AZ failover
The default configuration of Crunchy Postgres for Kubernetes is specifically designed to use High-Availability (HA) configurations for PostgreSQL clusters. These settings ensure that the Postgres instances forming a PostgreSQL cluster are deployed by the Crunchy Postgres for Kubernetes in a manner that prioritizes HA cluster architecture as the standard setup.
Minimal downtime and Minimal disruption
Crunchy Postgres for Kubernetes’s automated self healing tools will respond to hardware or data center failures in seconds, restarting failed databases and ensuring that applications have access to the primary database at all times. Rapid leader elections in case of issues to ensure data safety and application continuity.
Single or Many Kubernetes cluster
Deploy your PostgreSQL databases across multiple datacenters in a single stretched kubernetes cluster, or several regions each with their own Kubernetes deployments.
Self-healing
Crunchy Postgres for Kubernetes leverages the capabilities of Kubernetes to automatically restart failed containers, replace them as needed and terminate containers failing health checks. Building upon these foundational features, Crunchy Postgres for Kubernetes introduces PostgreSQL-specific enhancements. These enhancements include failing over the primary database to a healthy container within seconds and ensuring that restarted databases promptly replay backups and transactions to rapidly catch up to the current state.
Contact Crunchy Data
Looking for more details or need assistance? Reach out to us and our expert team will gladly assist you.