Crunchy Data Warehouse
Postgres for Parquet and Iceberg
With Crunchy Data Warehouse, you can now effortlessly query your Parquet and Iceberg tables directly from Postgres, with no need to move data around or manage complex ETL processes.
Query your data where it lives
Crunchy Data Warehouse leverages your existing object store to bring you the best features of Parquet and Iceberg without leaving Postgres
SQL Standard
Create foreign tables in Postgres to query using SQL syntax against your data lake.
Simple
Easily access and query large batches of files with data management capabilities of Iceberg.
Catalog access
Query across complex and large data lakehouse environments and data catalog.
Query across a large batch of unstructured or semi-structured Parquet files
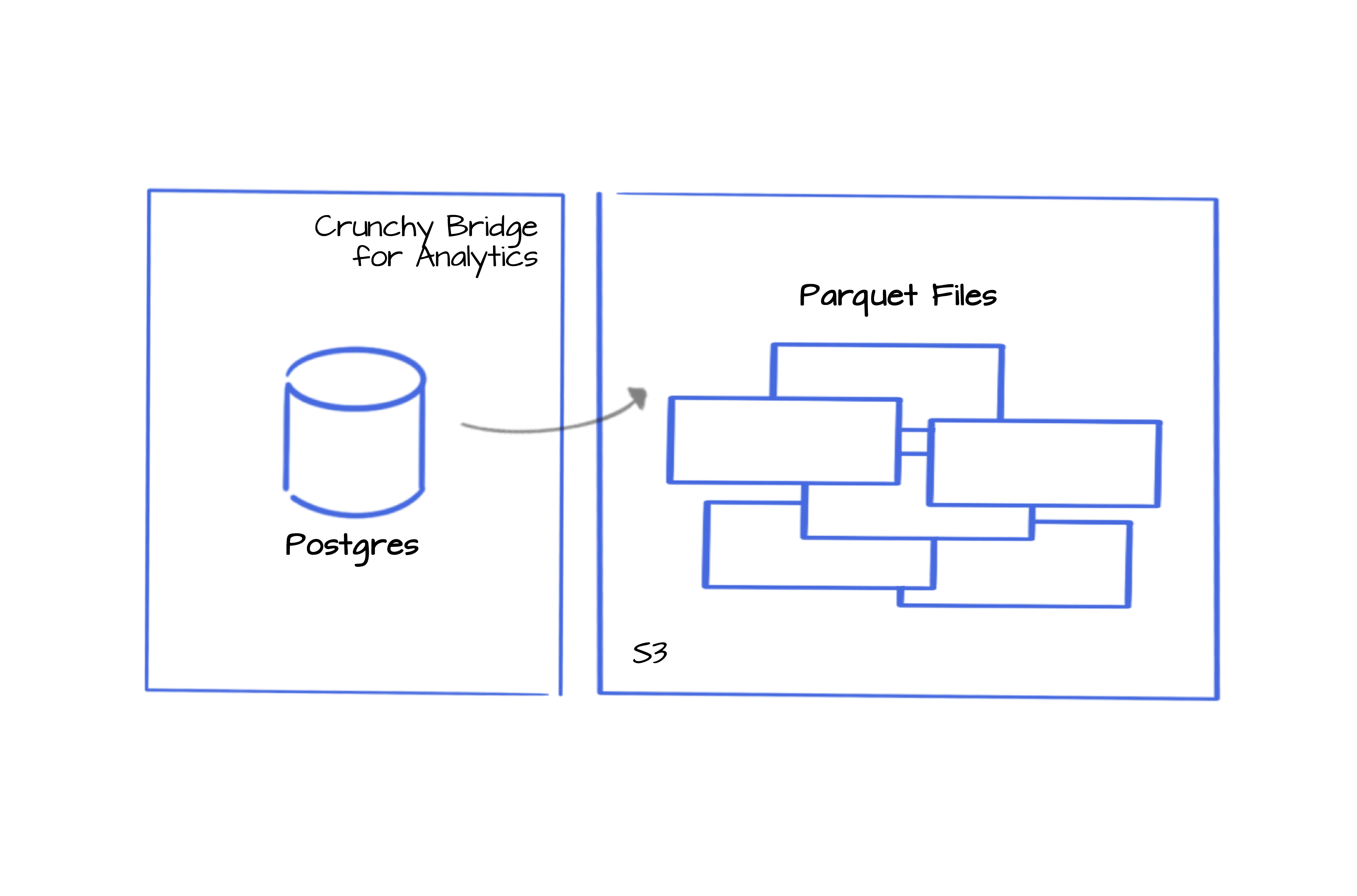
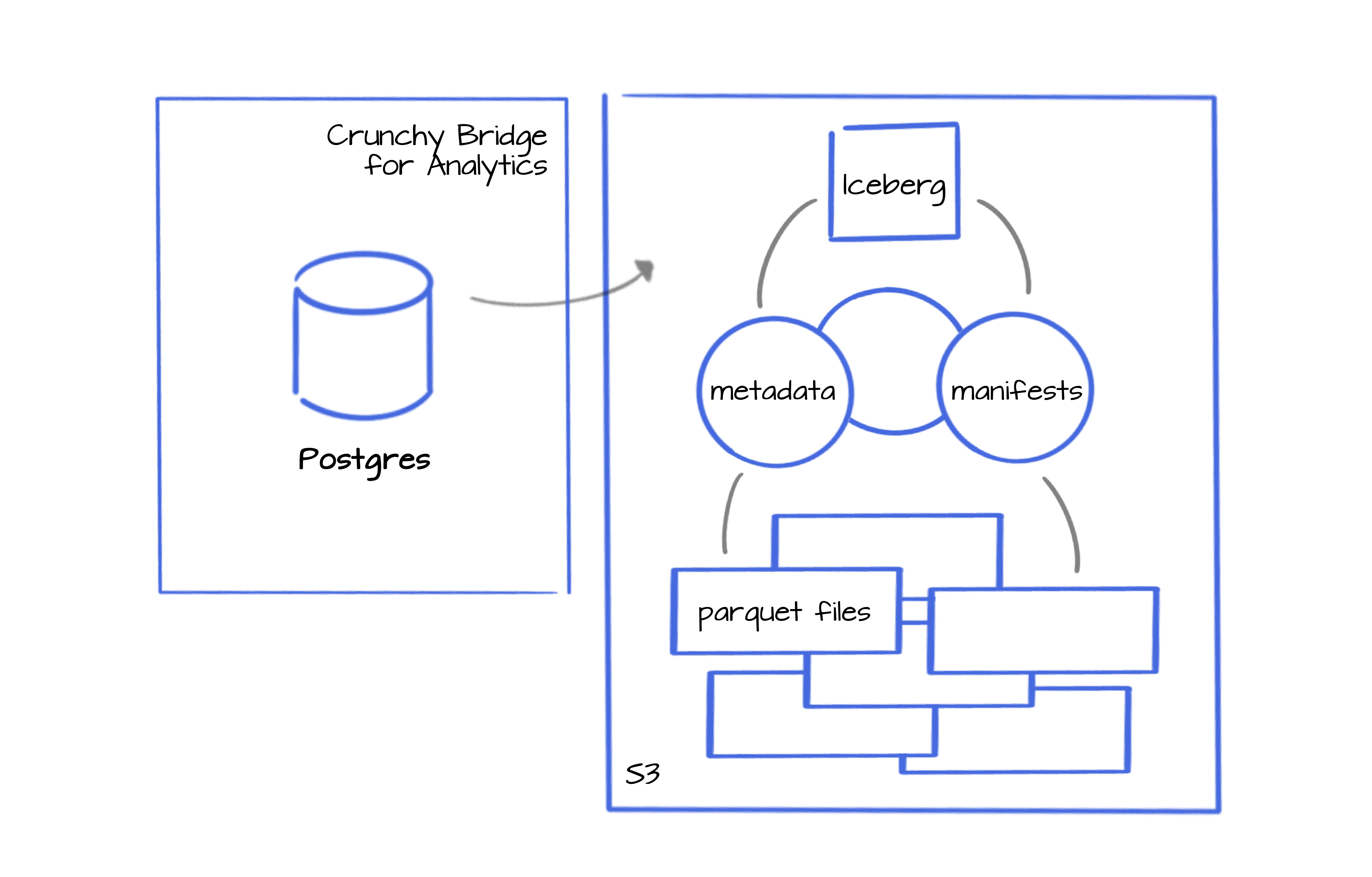
Or query using the Iceberg table containing your Parquet file metadata
Benefits of Postgres + Parquet for Data Analytics
Cost effective
Compress and store huge sets of data efficiently in cost-effective cloud storage such as S3 using Parquet format
Unified Querying
Remove complex data transformations or migrations and query using native PostgreSQL tools
High Performance
Leverage vectorized execution and parallelism to accelerate query performance on Parquet and Iceberg tables.
Intelligent local caching
Achieve high query performance and minimize network costs with built-in NVMe caching.
Flexibility
Use Postgres for transactional data and still achieve high-speed analytical queries on your Parquet and Iceberg tables.
Simplified Data Management
Reduce complexity by simplifying and removing complicated ETL or ELT pipelines.
Benefit from the full range of Parquet features
Crunchy Data Warehouse supports the key features of the Parquet file format, ensuring you can leverage its advantages for your analytical workloads.
Columnar Storage
Parquet's columnar storage format allows for highly efficient data retrieval and storage, particularly for read-heavy analytical workloads. By storing data in columns, and reading only the relevant columns Parquet enables faster querying and reduced I/O operations. Our integration takes full advantage of this format, providing high-speed access to your data and optimizing query performance.
Data Compression
Parquet supports various data compression algorithms, such as Snappy and Gzip, which help reduce storage costs and improve query performance by decreasing the amount of data read from disk. Our integration ensures that compressed Parquet files are handled seamlessly, allowing you to benefit from reduced storage requirements and faster data access.
Predicate Pushdown
Predicate pushdown is a critical optimization feature that allows filters to be applied directly at the storage level, reducing the amount of data read and processed during query execution. Our integration leverages this feature to improve query performance by pushing down predicates to Parquet files, ensuring that only relevant data is read and processed.
Nested Data Structures
Parquet's support for nested data structures, such as arrays, maps, and structs, allows for more complex data representations and querying capabilities. Our integration handles these nested data structures efficiently, enabling you to have access to any data type that Parquet offers, natively in Postgres.
Automatic Schema Inference
Parquet stores metadata along with the data, which includes information about the schema of the file. We use this metadata to extract the column definitions, and automatically create a table for any given parquet file.
Partial file retrieval
Parquet's columnar storage format allows for partial file retrieval, meaning only the required columns are read during a query. This significantly reduces I/O and improves performance for analytics workloads where queries often focus on specific subsets of data.
Analyze 100s of raw files without ETL complexity
Crunchy Data Warehouse eliminates the need for complicated ETL and ELT data pipelines, reducing the overhead associated with data movement and format conversion. Streamline your workflow with less operational complexity without compromising features or performance.

Learn more about Postgres for Parquet and Iceberg via Crunchy Data Warehouse
Contact Crunchy Data
Looking for more details or need assistance? Reach out to us and our expert team will gladly assist you.